SoQal: Selective Oracle Questioning for Consistency Based Active Learning of Cardiac Signals
The healthcare industry now generates troves of data from distinct modalities on a daily basis. Such data modalities range from the micro of genomics, which capture information at the sub-cellular level, to the macro of physiological signals and medical images, which capture information at the organ level. Extracting clinically-meaningful insight from such data can be achieved via deep learning algorithms, which are notoriously data-hungry (read: require abundant labelled data).
Oftentimes, however, the rate with which this data are generated far exceeds the rate with which they can be realistically annotated by medical professionals. For example, in low-resource clinical settings, medical professionals may lack the necessary expertise or simply be unavailable to provide annotations. Conversely, in high-resource clinical settings, medical professionals are inundated by the sheer number of requests for annotations, exacerbating the increasingly-observed phenomenon of physician-burnout. As such, clinical settings are now commonly characterized by the presence of limited labelled data and abundant unlabelled data. One way to deal with this scenario is through active learning, as outlined next.
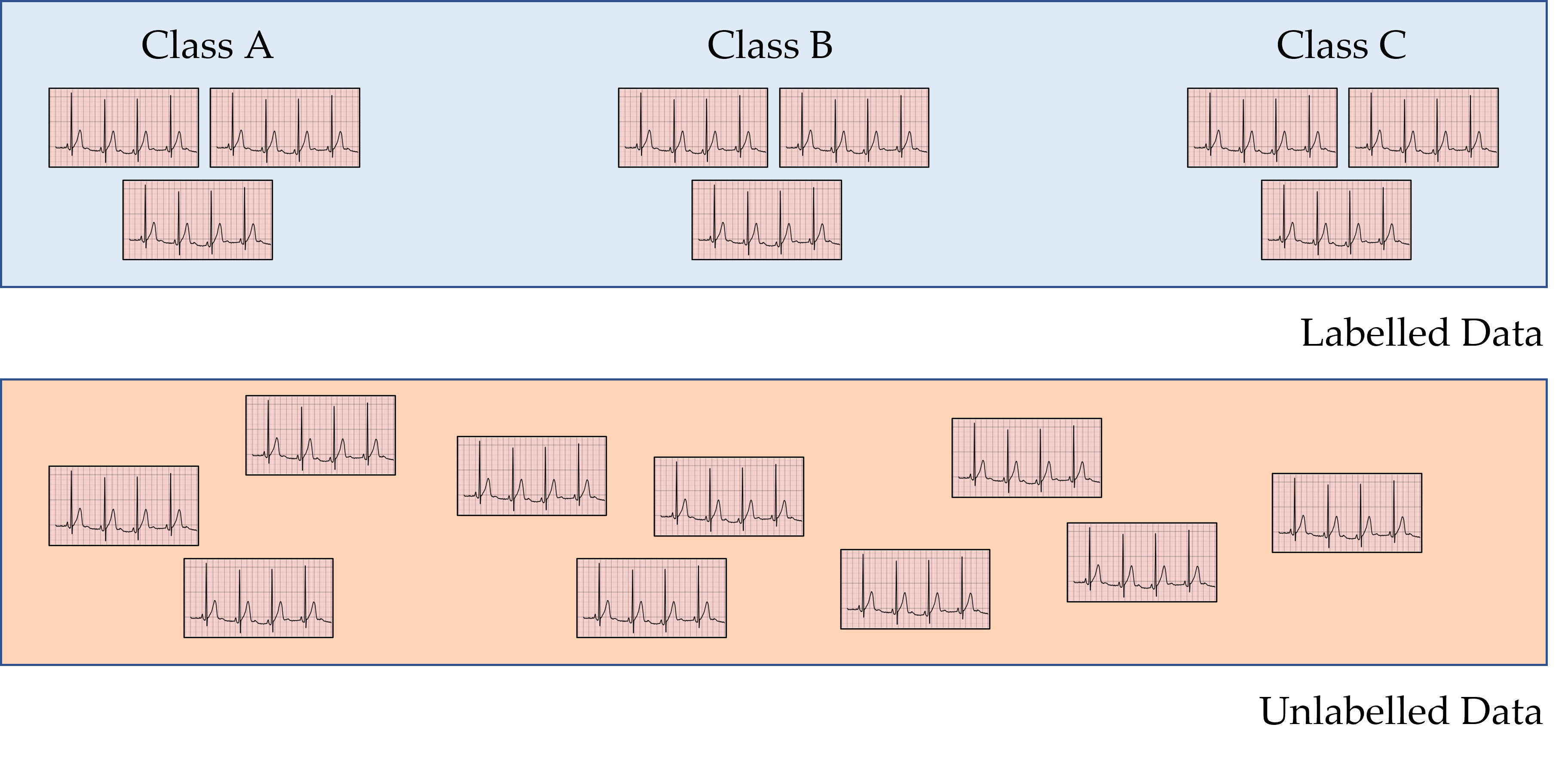
Introduction to Active Learning
An active learning framework allows neural networks to achieve strong performance while simultaneously exploiting a labelled and unlabelled set of data and minimizing the annotation burden placed on an oracle (e.g., a physician). All such frameworks typically iterate over four main steps: 1) train - a neural network is trained on some existing labelled data, 2) acquire - the same network is tasked with acquiring unlabelled data points, 3) label - an oracle (e.g., physician) is tasked with labelling such acquired data points, and 4) augment - the neural network is trained on the existing and newly-labelled data points. Whereas previous work in the literature commonly focuses on either step 2 (acquisition) or step 3 (annotation), we modify both.

Limitations of Existing Methods to Active Learning
How does previous work acquire unlabelled datapoints?
To acquire datapoints from a pool of unlabelled data, active learning methods rank these datapoints from the most informative to the least informative. Given datapoints from two distinct classes (see below), it is believed that datapoints which are closer to the decision boundary are more informative than those farther away from the boundary. Previous work quantifies this proximity to the decision boundary via Monte Carlo Dropout (MCD), which first perturbs the parameters of a neural network to generate distinct decision boundaries, and identifies unlabelled datapoints whose network classification differs across the parameter perturbations. We show, however, that if such parameter perturbations are misspecified (e.g. by being too small in magnitude), this approach can fail to acquire otherwise informative datapoints, thus hindering the learning process.

How does previous work annotate newly-acquired unlabelled datapoints?
Previous work typically assumes the presence of an ideal oracle (e.g., physician) who is capable of providing correct annotations for any and all of the acquired unlabelled datapoints. This assumption, however, is unlikely to hold within healthcare where physicians can either lack expertise for a particular task (generating incorrect annotations) or simply be unavailable (not providing annotations at all).
Improving the Acquisition of Unlabelled Datapoints
How do we acquire more informative datapoints?
In order to overcome the limitations of Monte Carlo Dropout, we propose, in our ICML 2022 paper, a family of consistency-based active learning frameworks. Whereas MCD perturbs neural network parameters to identify datapoints in proximity to the decision boundary, we perturb the input datapoints themselves (which we refer to as Monte Carlo Perturbations) or both the input datapoints and the network parameters (which we refer to as Bayesian Active Learning by Consistency). The motivation for doing so is twofold. First, the perturbation of input datapoints is more understandable than the perturbation of parameters, thus providing machine learning practitioners with increased control and interpretability over the applied perturbations. Second, by perturbing both input datapoints and network parameters, we make it less likely to miss informative datapoints.

Improving the Annotation of Newly-Acquired Unlabelled Datapoints
How do we minimize the labelling burden placed on physicians?
Whereas previous work assumes that ideal oracles exist consistently throughout the learning process, we reduce our dependence on an oracle by dynamically determining whether, for each acquired unlabelled datapoint, to request a label from an oracle or to provide a network-based annotation (also known as a pseudo-label). They key insight here is that we delegate what would ordinarily have been annotated by an oracle to the neural network itself (prediction network below). Such a decision to delegate is performed by the oracle selection network, whose details are provided in the paper. In light of this selective process, we refer to this framework as selective oracle questioning in active learning (SoQal).
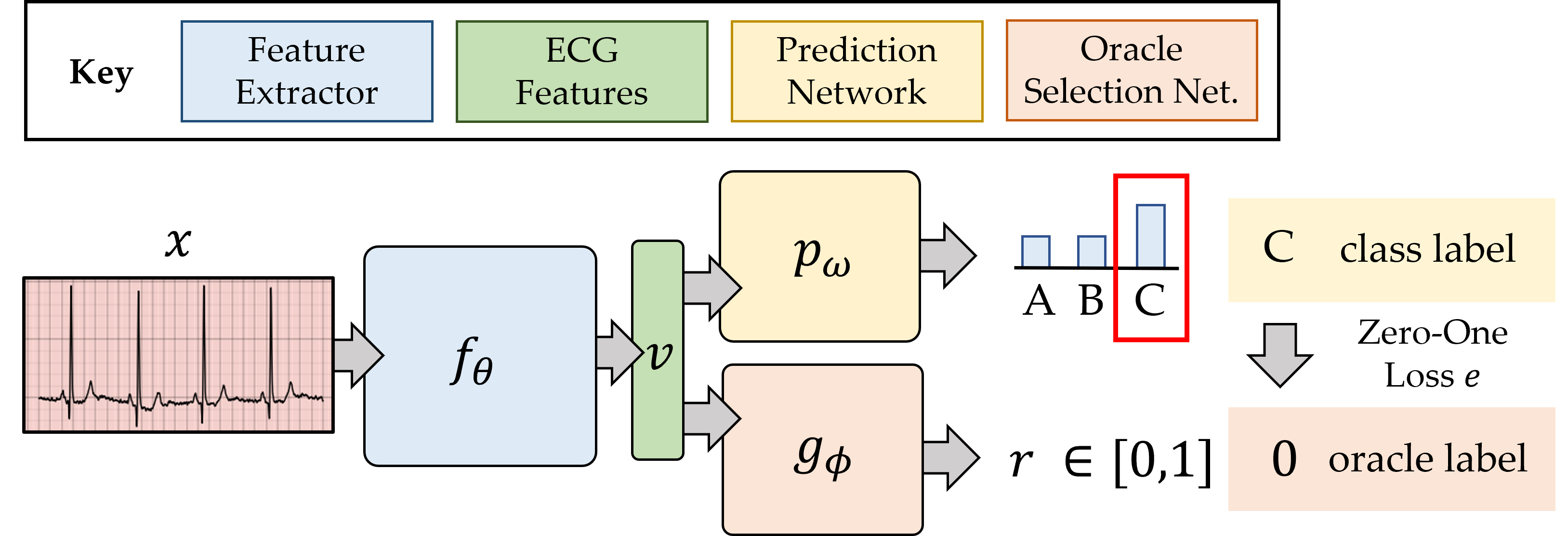
Active Learning Scenario 1 - No Oracle
How does our framework perform in the absence of an oracle?
We begin by exploring the performance of active learning frameworks without an oracle. Below, we illustrate the validation AUC of a network that is initially exposed to 30% of the labelled training data. We find that a network which exploits our consistency-based framework (BALC) learns faster than, and outperforms, those which exploit the remaining acquisition functions. For example, BALCKLD and BALDMCD achieve AUC around 0.69 after 20 and 40 epochs of training, respectively, reflecting a two-fold increase in learning efficiency.
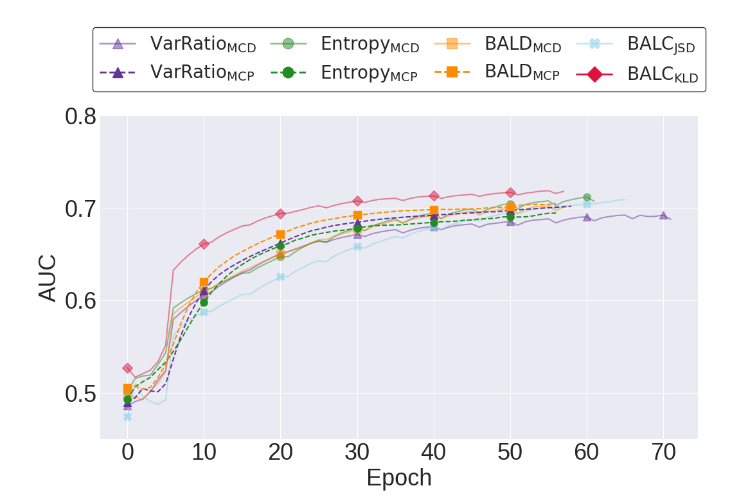
Active Learning Scenario 2 - Noise-free Oracle
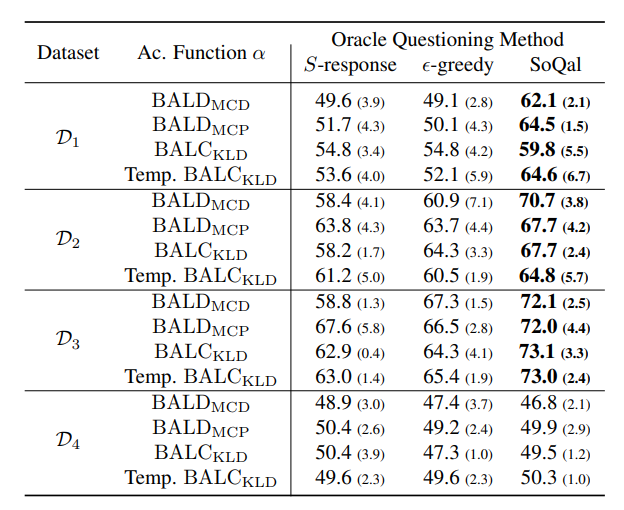
How does our framework perform in the presence of an ideal oracle?
Assuming the presence of a noise-free oracle, we now explore the effect of selective oracle questioning methods. In the table below, we present the results of these experiments across all datasets when the network is initially exposed to only 10% of the training data. We find that SoQal consistently outperforms several baseline methods, including S-response and epsilon-greedy across the first three datasets. Such a finding suggests that SoQal is well equipped to know when a label should be requested from an oracle.
Active Learning Scenario 3 - Noisy Oracle
How does our framework perform in the presence of an oracle who somtimes provides incorrect annotations?
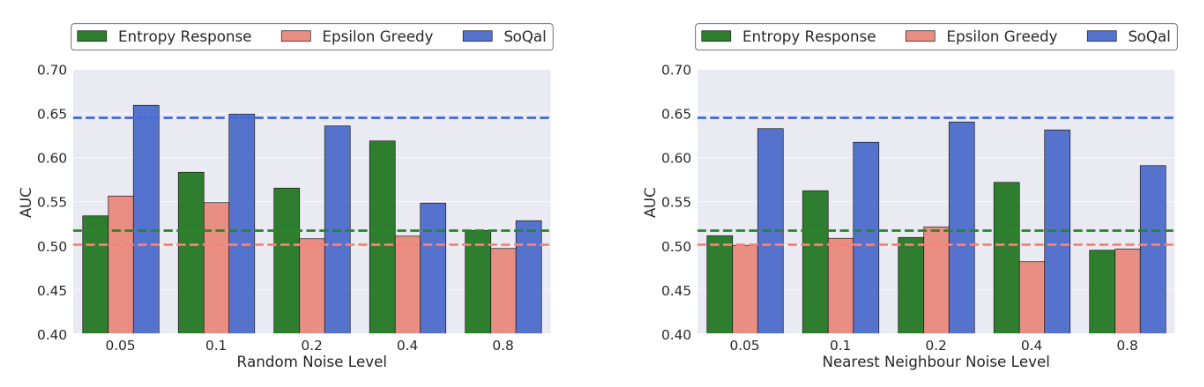
Building on the findings in the previous section, we now explore the performance of our oracle questioning methods with a noisy oracle. In the figure below, we illustrate the test AUC as a function of various types and levels of noise. We also present the performance with a noise-free oracle (horizontal dashed lines). We find that SoQal is more robust to a noisy oracle than epsilon-greedy and S-response. This is evident by the higher AUC of the former relative to the latter across different noise types and magnitudes. One hypothesis for this improved performance is that SoQal, by appropriately deciding when to not request a label from a noisy oracle, avoids an incorrect instance annotation, and thus allows the network to learn well.
Moving Forward
Where do we go from here?
We see several worthwhile avenues to explore in the near future. SoQal assumed that the annotations provided by the oracle, when requested, are consistently reliable. However, an oracle (e.g., a physician) is likely to experience fatigue over time and exhibit undesired variability in annotation quality. Such oracle dynamics are not accounted for by our framework yet pose exciting opportunities for the future. Moreover, our framework assumed that, at most, a single oracle was available throughout the learning process. However, clinical settings are often characterized by the presence of multiple oracles (e.g., radiologists, cardiologists, oncologists) with different areas and levels of expertise. We hope the community considers incorporating these elements into an active learning framework which would prove quite valuable given the realistic nature of such a scenario.
Acknowledgements
We would also like to thank Melhem Barakat for lending us his voice.